Codecs para videovigilancia en red.
Usualmente estamos familiarizados con términos como H.264, H.265 y posiblemente MJPEG, conocer qué son, cómo funcionan, cuáles son sus diferencias y porque usarlos es muy relevante en el diseño y la implementación de proyectos de videovigilancia, en esta nota lo analizamos.
Abordaremos el tema desde estos puntos:
Esencialmente, todo el video en los sistemas de videovigilancia en red tiene un proceso de compresión, de no ser así la demanda de almacenamiento y tráfico de red serían demasiado grande, incluso sería inviable para aplicaciones relativamente pequeñas.
Cuando la señal de video se digitaliza, inicialmente se descomprime y hay tres factores principales que inciden en el tamaño del video sin comprimir:
Para encontrar el tamaño total, se multiplica cada uno de estos factores.
A cada píxel se le asigna un valor representado por un número dentro de un rango. El rango determina la precisión con la que se puede definir el color y también tiene un gran impacto en el ancho de banda y tamaño de la imagen.
Los otros dos factores son mucho más fáciles de deducir, ya que son la resolución de la cámara, multiplicando el número de píxeles horizontales por los verticales y los fotogramas por segundo, como: 1 fps, 10 fps, 30 fps, etc.
Es común encontrar en muchos proyectos de videovigilancia que la mayoría de las cámaras graban entre 5 y 15 imágenes por segundo (FPS).
Así se puede reconocer que tan crítico y tan masivo puede llegar a ser el video sin comprimir. Por ejemplo; una cámara a color de 1080p a 30 fps. Sin comprimir seria:
16 bits X 2.073.600 pixeles x 30 FPS = 995,328,000 ≈ 1Gb/s
La multiplicación de esos tres factores da como resultado aproximadamente 1 Gb/s para video de 1080p/30fps sin comprimir. En un día, y con esta rata de información se tendría aproximadamente 12 TB de almacenamiento de una sola transmisión.
Si bien los discos duros continúan creciendo en cuanto a su capacidad de albergar información, un sistema de vigilancia sin comprimir de 16 cámaras que almacene durante 30 días necesitaría casi 6 PB de almacenamiento, se requerirían cientos de discos duros que tendrían un valor demasiado alto.

A pesar del enorme tamaño de la información de video sin comprimir, los sistemas de vigilancia típicos, de 16-32 cámaras normalmente se fabrican en sistemas de grabación no más grandes que un PC estándar o incluso en dispositivos más pequeños, y esto es gracias a los algoritmos de compresión o códecs.
La palabra CODEC significa compresión/descompresión en donde el proceso de compresión es el elemento central para reducir el consumo de ancho de banda y almacenamiento.
Asignar a cada píxel de cada fotograma un valor propio es algo impráctico y dispendioso, ya que la mayoría de las escenas están llenas de una pequeña cantidad de colores similares. La función de los códecs es comprimir el video al reducir la cantidad de valores registrados y al tiempo se identifican qué píxeles tienen valores iguales o similares, lo que le permite al final, transmitir cantidades mucho más bajas de bits.
Hay dos enfoques fundamentales para la compresión: intra-imagen e inter-imagen. Es muy importante comprender las distinciones entre los dos, ya que afectan el consumo de ancho de banda, los requisitos de potencia de procesamiento y calidad de imagen.
Todos los códecs admiten la compresión dentro del cuadro, pero algunos solo admiten la compresión tanto dentro como entre cuadros.
La compresión intra-cuadro se realiza dentro de los cuadros y aprovecha la redundancia o similitudes dentro de los cuadros, sólo analiza un cuadro o imagen a la vez, procesando al máximo la misma y obviando las similitudes que hay en la imagen.
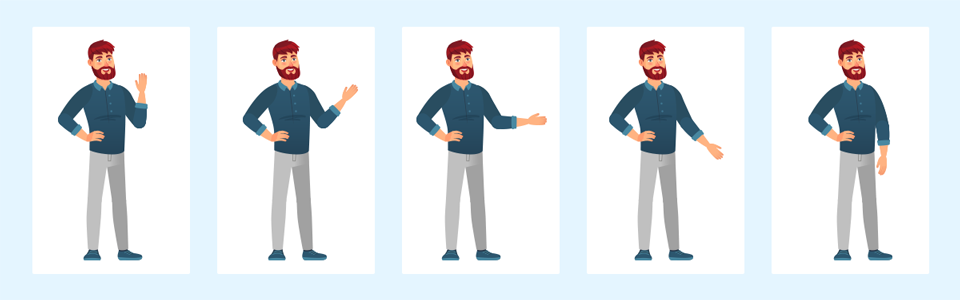
Aunque el video es una serie de imágenes, la compresión intra-cuadro ve solo un cuadro a la vez, ignorando la secuencia de imágenes.
La ventaja es que esto es simple de hacer computacionalmente y se comprime significativamente el video. Por ejemplo, una transmisión de video de 1080p/30 fps que utiliza una compresión intra-cuadro como MJPEG puede reducir su tasa de bits de ~1000 Mb/s a ~40 Mb/s. Sin embargo, la desventaja es que para los flujos de video actuales puede ser insuficiente el resultado de la compresión.
Al usar la compresión entre cuadros, no solo se codifica el video dentro del cuadro, sino que el códec compara los cuadros adyacentes para comprimir aún más la imagen. Esto es factible porque a menudo cambia muy poco de un cuadro al siguiente. Por ejemplo, usando la misma escena de una persona saludando, la compresión entre cuadros enviaría solo el brazo del sujeto.
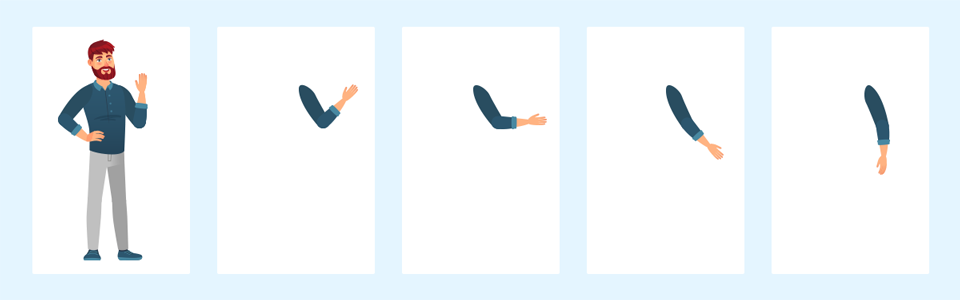
Con gran parte de una escena que permanece estática, enviar solo cambios en la escena ahorra ancho de banda y almacenamiento de manera sustancial. Por ejemplo, la misma transmisión de 1080p/30 fps que podría necesitar 40 Mb/s con MJPEG, y con un códec entre-cuadro, puede necesitar solo 4 Mb/s con H.264.
Sin embargo, la principal desventaja de la compresión entre fotogramas es que es mucho más exigente desde el punto de vista de procesamiento de datos, lo que puede aumentar los riesgos de rendimiento y calidad.
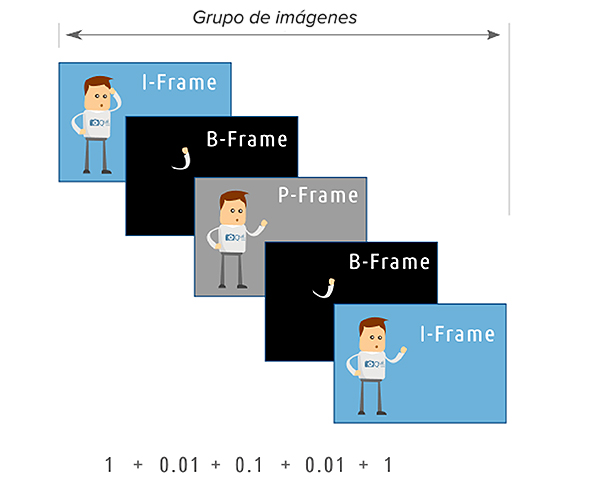
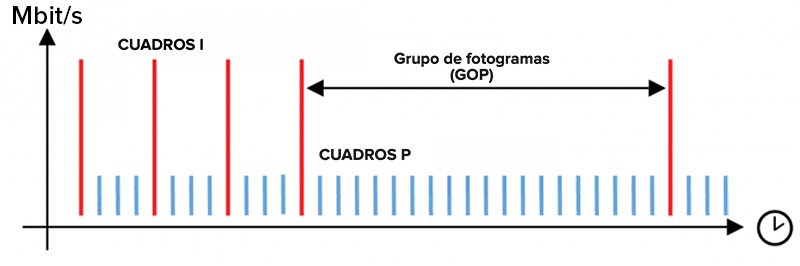
Hay dos tipos de cuadros comunes en la compresión entre-cuadros que se dan en códecs ampliamente usados como H.264/H.265, estos son cuadros I y cuadros P.
El primer cuadro en un grupo de imágenes se denomina cuadro I, abreviatura de intracodificado, y es esencialmente un cuadro completo de video, a diferencia de solo los cambios que se encuentran en los cuadros P. La distancia entre dos cuadros I se conoce como intervalo de cuadros I, GOV (grupo de vídeo) o GOP (grupo de imágenes).
Los cuadros P hacen referencia a los cambios de la imagen completa del cuadro I inicial y envía solo los cuadros que representan los cambios en la escena. Los cambios pueden ser pequeños, como el ruido digital o el pequeño movimiento del follaje, o grandes, como una cámara PTZ que se mueve de un preajuste a otro. La P en P-frame significa “predictivo”.
A partir del inicio de la última década (2020) la mayoría de las implementaciones usan el códec H.265, aunque muchos modelos de cámaras todavía usan H.264. Los problemas de procesamiento con H.265 han disminuido a medida que ha mejorado la compatibilidad con la decodificación en el hardware, aunque H.264 sigue siendo menos exigente en procesamiento de hardware para algunas aplicaciones se prefiere el códec H.264 al H.265.
El formato de compresión MJPEG puede aún estar vigente pero raramente se usa, solo en algunas implementaciones, principalmente en aplicaciones especializadas como LPR y otras funciones de análisis. Sin embargo, los fabricantes han comenzado a limitar el soporte para MJPEG, y algunos modelos ya no brindan una transmisión con MJPEG.
Los sistemas de videovigilancia han tenido desarrollos importantes de códecs propietarios. Las cámaras IP codifican el video en la misma cámara y luego necesitan transmitir este video codificado a una grabadora o VMS para decodificarlo, almacenarlo y administrarlo. Los códecs patentados aumentan la complejidad del almacenamiento, la gestión y la visualización de video, ya que cada uno debe integrarse en el VMS en cuestión.
En los últimos años, los códecs inteligentes H.264+ y H.265+ se han vuelto comunes, con el objetivo de reducir aún más las tasas de bits en comparación con el estándar H.264/5. La forma exacta en que funcionan estos códecs inteligentes varía, pero generalmente utilizan dos técnicas, que se analizan a continuación.
En lugar de aplicar el mismo nivel de compresión a toda la escena, los códecs inteligentes ajustan dinámicamente la compresión para la actividad en el campo de visión de la cámara. Por ejemplo, observando la imagen de abajo, la compresión podría establecerse en “baja” para que las porciones de la escena en donde hay movimiento de personas se mantenga en calidad alta de video, pero el entorno al ser estático puede establecerse en compresión “alta”, ya que no se requiere constantemente detalles con alta resolución.
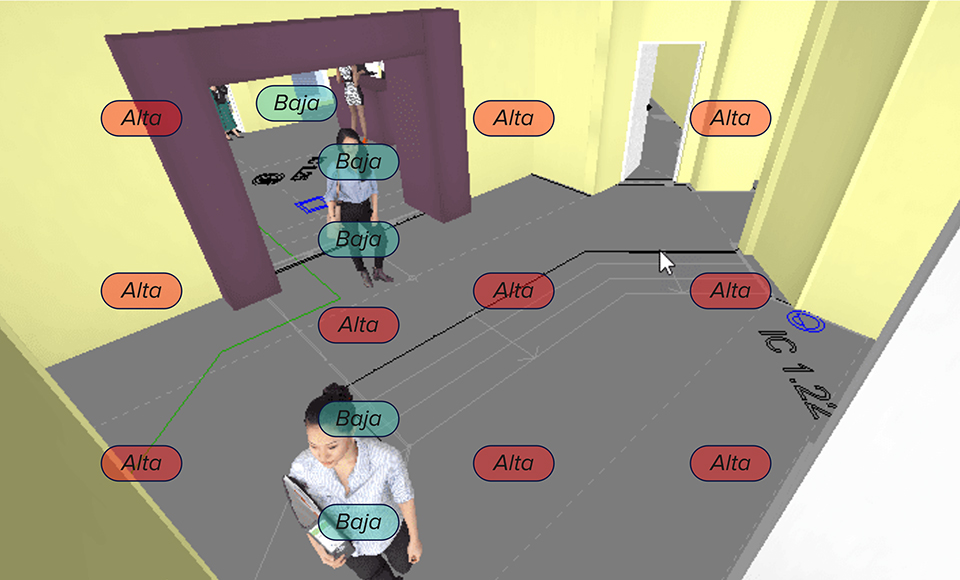 Compresión dinámica: varía dependiendo de la actividad o cambio de escena.
Compresión dinámica: varía dependiendo de la actividad o cambio de escena.
En segundo lugar, los códecs inteligentes suelen ajustar dinámicamente el intervalo de cuadros I en función de la actividad en la escena. Los cuadros I llevan toda la información de la escena y son mayores que los cuadros P, que representan solo los cambios en la escena.
Por lo tanto, si una escena tiene poco o ningún movimiento, la cámara envía cuadros I, con poca frecuencia, por lo que el ahorro en cuanto a velocidad de bits y ancho de banda es significativo, pero cuando se detecta actividad en la escena, se envía inmediatamente un cuadro I y vuelve a la normalidad, con intervalos de fotogramas I, más seguidos, mientras la actividad continúa.

Los códecs inteligentes han probado ser bastante eficientes reduciendo significativamente las tasas de bits, incluso en escenas dinámicas, y son aún más eficientes en escenarios de imágenes que poco cambian, hasta un 95 %. Estos códecs son más efectivos en escenas fijas de aplicaciones en espacios interiores con pocos cambios en escena ya que los intervalos de cuadros I, permanecen más largos y la compresión es más alta debido a la falta de actividad.
Hay algunos problemas que pueden deteriorar la calidad del video transmitido, esto son:
Si los niveles de compresión se configuran demasiado altos, la calidad del video se degradará. Estos problemas a menudo son visibles en escenas complejas, donde hay mucha acción: intersecciones vehiculares, multitudes de personas, etc.
Si se usa CBR pero la tasa de bits se configura demasiado baja, la calidad del video se degradará.
Si bien múltiples fabricantes proponen muchos códecs alternativos, es poco probable que todos lleguen a ser estandarizados y por ende obtengan una amplia adopción en la vigilancia.
Algunos desarrolladores afirman ahorros masivos de ancho de banda de sus códecs patentados, sin embargo, esto requeriría que tanto los fabricantes de cámaras como los desarrolladores de VMS implementaran estos códecs en sus productos.
Dadas las reducciones significativas de la tasa de bits de los códecs inteligentes, que son compatibles con la mayoría de las grabadoras/VMS como H.264+ y H.265+ actuales, seguirán teniendo desarrollo para agregar mejoras en estos códecs que ya son de uso masivo, pero sin duda, algunos fabricantes seguirán presentando mejoras en sus desarrollos para ser diferenciadores de mercado pero no generalizados a todas las marcas, como un estándar.
La mejor combinación de códecs para la mayoría de los casos de uso son aquellos que forman parte de la base de su desarrollo del H.264 ya que nuevas versiones de los códecs inteligentes como H.265+ mejoran significativamente la eficiencia de H.264 con inconvenientes mínimos.
H.265 se ha venido fortaleciendo, pero en muchos casos podrán prevalecer los desarrollos de algunas marcas debido a que también este, tiene limitaciones. Sin embargo, es usado ampliamente en soluciones completas de cámaras IP, NVRs y VMS de un solo fabricante o en donde se permite la integración de terceros por medio de ONVIF y de este modo se minimizan los problemas de compatibilidad.
MJPEG sigue siendo un nicho para aplicaciones especializadas en especial analíticas de video que requieren información constante y más completa de la escena sin que la compresión entre fotogramas sea lo más relevante.
Los formatos de compresión son claves a la hora de especificar el tipo de cámaras según cuál será su objetivo y aplicación, se debe tener especial atención en que los sistemas de grabación y el VMS puedan procesar cuantos formatos de compresión se tengan establecidos en los tipos de cámaras. Así como determinar que tanta compresión podemos aplicar en los diferentes escenarios sin perder los detalles relevantes en la escena de modo que se genere una relación costo beneficio entre el video útil y su consumo en almacenamiento y transmisión de datos.